
Digital twins are virtual replicas of physical systems, providing real-time insights by syncing with sensor data. The key to their success lies in efficient data storage, preparation, and retrieval. Here's what you need to know:
- Data Storage: Use systems like Hadoop HDFS for historical data and NoSQL databases for real-time updates. The "Lakehouse" model combines both into one platform for simplicity.
- Data Preparation: Clean sensor inputs, reduce dimensions with PCA, and align data across time and space to ensure accuracy and speed.
- Data Retrieval: Leverage edge computing for low-latency updates, AI-powered queries (like RAG) for smart searches, and mathematical techniques (e.g., Euclidean distance) for precise matches.
Platforms like Anvil Labs simplify the process by centralizing data hosting, offering processing services at $3 per gigapixel, and integrating AI tools for actionable insights. Efficient management can cut operational costs by 20-30%, making digital twins a game-changer for industries.

Digital Twin Data Management: Storage, Preparation, and Retrieval Process
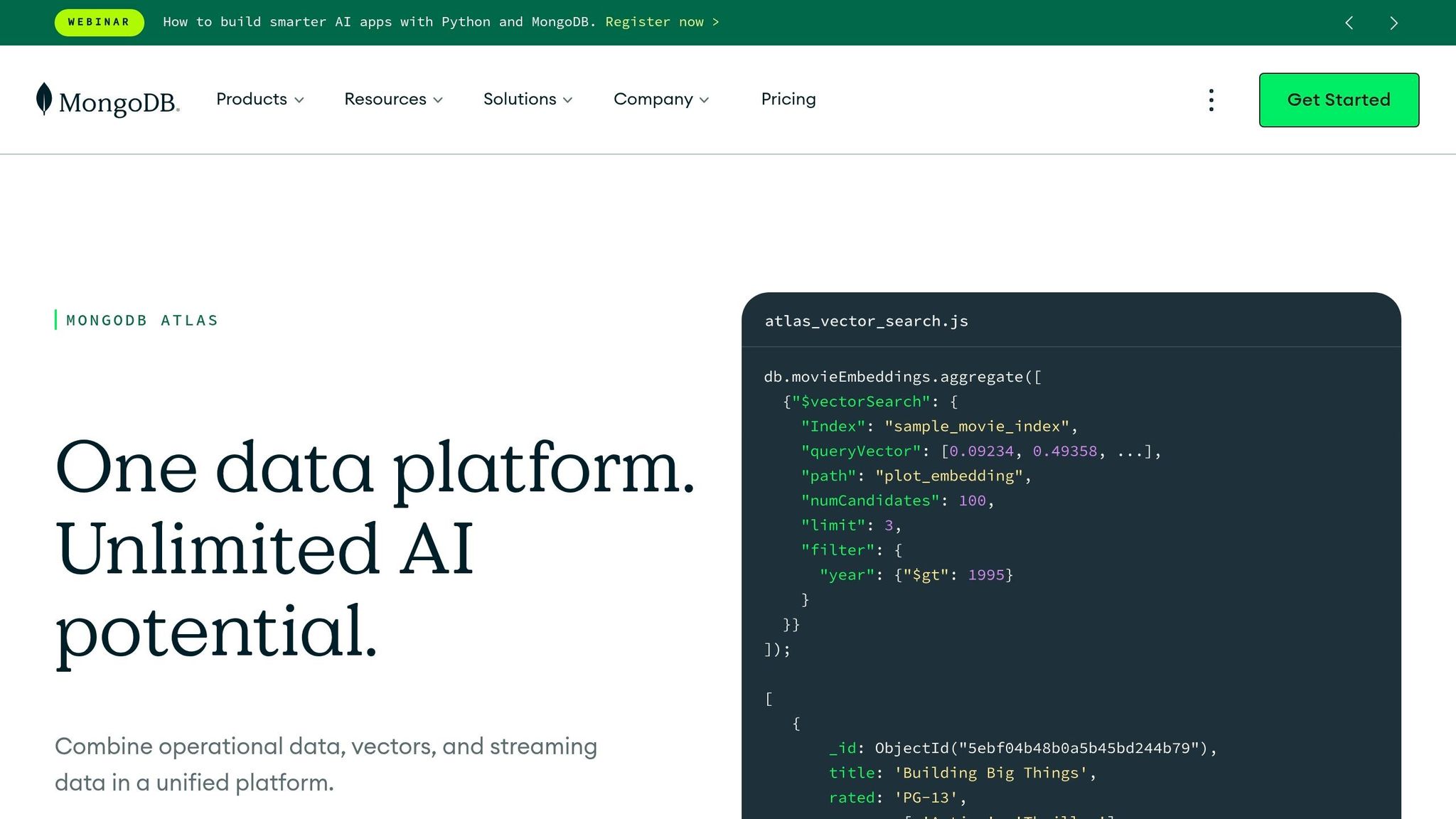
Manufacturing Digital Twin Data Modeling using MongoDB
sbb-itb-ac6e058
Data Storage Strategies for Large-Scale Digital Twins
Managing data for large-scale digital twins isn't just about storing information - it's about handling continuous sensor streams and massive archives efficiently. With data volumes often reaching terabytes or even petabytes, traditional databases can struggle, especially as query performance declines with growing datasets.
To tackle this challenge, selecting the right storage architecture is key. Distributed file systems, like Hadoop HDFS, are ideal for archiving huge historical datasets thanks to their high bandwidth. On the other hand, NoSQL and distributed databases excel at handling real-time, unstructured data with near-instant query responses. These systems are flexible, allowing for the seamless addition of new sensor data types. Modern designs use techniques like sharding and partitioning to ensure fast access to time-series data, no matter how large the dataset grows.
An emerging approach is the "Lakehouse" model, which blends real-time and historical data storage into a single system. Using formats like Delta Lake, organizations can organize raw sensor data in a "Bronze" layer while storing curated data for analytics - all within one environment. This eliminates the hassle of maintaining separate databases for operational and historical needs.
"By combining Lakebase with the Delta Lake format, we get real-time performance and cost-efficient history without the hassle of complex ETL or maintaining duplicate databases".
This unified approach sets the foundation for tailoring storage solutions to specific operational demands.
Using Hadoop HDFS and NoSQL Databases

Hadoop HDFS is built for heavy-duty batch processing and long-term archiving. Its design - featuring a 128 MB block size and a replication factor of 3 - ensures data durability by distributing copies across different racks, reducing the risk of data loss during hardware failures. HDFS operates on the principle of bringing computation to the data, which minimizes network congestion and makes it ideal for handling digital twin datasets that span gigabytes to terabytes.
Meanwhile, NoSQL databases, like Apache Cassandra, are better suited for real-time operations. These systems are designed for distributed architectures and excel in write-heavy environments where sensors constantly push data. They can handle diverse data types, including geospatial, JSON, and time-series formats.
The key is knowing when to use each. HDFS shines for batch analytics and long-term storage, while NoSQL databases are perfect for low-latency, real-time monitoring with flexible schemas. Many organizations use both, with NoSQL handling real-time ingestion and HDFS managing historical archives.
For immediate, high-speed data needs, in-memory databases come into play.
Leveraging In-Memory Databases
In-memory databases store data in RAM, making them incredibly fast - perfect for live sensor data processing. However, because RAM is expensive and has limited capacity compared to disk storage, these databases are best for managing current operational data and recent time-series snapshots. Older data can be moved to columnar warehouses for deeper, long-term analysis.
"Columnar databases optimize how data is arranged for thinking (analytics). In‑memory databases optimize where data lives for speed (operational latency)." - Nageshwar, Software Architect
This hybrid setup ensures real-time decision-making while keeping costs manageable for historical analysis and predictive tasks.
Optimizing Storage with Columnar Formats
Columnar data formats, like Apache Parquet, are game-changers for storing and querying digital twin data. Instead of saving data row by row, these formats store it by column, allowing systems to access only the specific metrics needed for a query.
The benefits are striking. A 10 GB CSV file, for instance, can be compressed into a 1–2 GB Parquet file. If a query references just two columns in a table with 100 columns, a columnar system might only read 2% of the data. This efficiency makes analytical queries on Parquet files 10 to 100 times faster than on row-based formats like CSV or JSON.
Advanced techniques, such as delta encoding and clustering by timestamps, further enhance compression and query performance. Parquet also stores metadata, like min/max values for data chunks, enabling systems to skip irrelevant data blocks during queries - reducing unnecessary disk reads. However, since columnar formats aren't ideal for single-row updates, data is often streamed into a row-oriented buffer first and then converted to Parquet in batches.
These optimizations are critical for ensuring digital twins deliver timely, accurate insights.
Preparing Digital Twin Data for Retrieval
Getting digital twin data ready for retrieval starts with preparing raw sensor data. This means eliminating noise, duplicates, and mismatched timestamps. The goal is to turn messy, unprocessed inputs into clean, organized datasets that allow for quick and reliable access. This preparation works hand-in-hand with solid storage strategies to ensure that data is not only stored properly but is also ready for fast retrieval when needed.
The process generally involves two main steps: cleaning and reducing data volume, followed by synchronizing information across time and space. Together, these steps help maintain accuracy while improving performance and retrieval speeds for large-scale digital twin systems.
Data Cleaning and Dimensionality Reduction
The first step is to clean the data by filtering out sensor errors, duplicates, and noise. Compaction algorithms are often used to eliminate redundant information and reduce unnecessary transmission. For instance, if several sensors record the same temperature at the same time, cleaning tools consolidate these readings into one entry.
Dimensionality reduction is another key technique. It simplifies high-dimensional datasets while keeping the most important features intact. Methods like Principal Component Analysis (PCA) extract critical variables from complex datasets, discarding less relevant dimensions. This makes the data easier to work with and faster to query, without losing accuracy.
Neural network autoencoders are also useful for compressing multi-modal data - such as combining thermal imagery with 3D models - into a single, unified format. Weighted averages can merge different data types, reducing dimensions while retaining the variety of inputs. This approach is particularly helpful for industrial applications that demand scalable and efficient data retrieval.
Reports indicate that 30% of digital twin projects now use prediction-focused models that depend on pre-processed, reduced-dimension data. These models are designed for faster analysis, cutting down on computational demands and enabling real-time decision-making.
Temporal and Spatial Alignment
Once the data is cleaned, aligning it across time and space ensures even greater retrieval efficiency. Temporal alignment involves synchronizing timestamps from various sources, whether they're real-time or historical. Techniques like the least squares method help minimize mismatches in time-series data by fitting mathematical models to align sequences. This is especially important when sensors operate on different clocks or sampling rates.
Spatial alignment, on the other hand, ensures that data is mapped to a common coordinate system. This is crucial for accurate 3D visualization and spatial queries. For example, GPS coordinates, camera feeds, and LiDAR scans need to be registered to the same reference frame. Preprocessing techniques, such as least squares, align physical data points across these sources.
A great example of this in action comes from Ferrovie dello Stato Italiane, which, in 2022, created a digital twin for over 10,000 miles of rail infrastructure. They cleaned and aligned sensor data from cameras and GPS using ArcGIS for spatial visualization. Advanced 3D registration algorithms achieved a 95% alignment accuracy, resulting in a highly interactive and accurate system.
Algorithms like Pearson correlation and K-means clustering can also uncover relationships between variables, improving retrieval accuracy by 20-30% in predictive models. Aligned datasets create networks where variables are represented as nodes, and their relationships form the edges. This structure speeds up knowledge extraction and reduces query response times significantly.
Currently, about 24% of digital twin projects focus on asset interoperability, often using standardized frameworks from organizations like the Digital Twin Consortium. These frameworks ensure smooth integration after data cleaning and alignment. As real-time data fusion platforms become more common - handling inputs from sensors alongside external sources like weather data - temporal and spatial synchronization is becoming increasingly critical.
Data Retrieval Techniques for Digital Twins
Getting digital twin data quickly and accurately is a must. Techniques like edge computing, AI-driven queries, and mathematical matching play a big role in ensuring timely and reliable insights. Just like data storage and preparation, efficient retrieval is key to keeping digital twins dependable. Modern approaches combine these methods to deliver the right information exactly when it’s needed.
These methods are designed to meet the critical needs of digital twin systems: seamless two-way data exchange, low latency, and intelligent query handling. Let’s break down each technique and its role in optimizing digital twin performance.
Real-Time Synchronization and Edge Computing
Real-time synchronization ensures that physical assets and their digital counterparts stay in sync through continuous sensor updates. This immediate, two-way communication is vital for keeping digital twins accurate and up-to-date.
Edge computing makes this possible by processing data right where it’s generated - at the network’s edge - instead of sending everything to a central cloud server. This reduces delays and speeds up decision-making. For example, in industrial settings, edge devices can handle calculations locally and only send critical results to the cloud. This means operators can quickly address equipment issues without waiting for data to travel back and forth.
AI-Powered Queries with RAG (Retrieval Augmented Generation)
Building on edge computing, AI-powered queries take data access to the next level. By combining retrieval mechanisms with generative AI models, these queries perform smart, context-aware searches across digital twin datasets. RAG (Retrieval Augmented Generation) adds contextual data to refine results. It retrieves relevant information first and then uses that context to generate more accurate answers or predictions.
This method shines in predictive maintenance, which accounts for 21% of all digital twin projects. RAG adapts dynamically using machine learning techniques like classification, regression, and anomaly detection. For instance, when analyzing a wind turbine’s performance, RAG can pull together historical sensor data, weather trends, and maintenance records to provide a complete analysis instead of fragmented data points.
It works even better when paired with neural networks that merge different types of data - such as thermal images, 3D models, and LiDAR scans - into unified formats. This enables RAG to search across multiple data types simultaneously, delivering deeper insights.
Using Euclidean Distance for Data Matching
Euclidean distance is a mathematical tool that measures the straight-line distance between two points in multi-dimensional space. It’s particularly useful for checking how closely data points align in digital twin systems. After cleaning and reducing data dimensions, this technique ensures that virtual model points align with real-world sensor readings.
In systems where variables are represented as nodes and their relationships as edges, Euclidean distance validates these connections. For example, in asset interoperability projects - which make up 24% of digital twin implementations - this method standardizes data extraction from sources like LiDAR and orthomosaics.
When paired with alignment techniques like least squares, Euclidean distance provides a final layer of verification. By removing residual noise, it ensures the digital twin accurately reflects the physical world. Platforms like Anvil Labs rely on these tools to maintain precision across various input types, from 3D models to thermal imagery.
How Anvil Labs Handles Digital Twin Data Retrieval
Anvil Labs has developed a platform designed to simplify and optimize digital twin data retrieval. By centralizing asset hosting, simplifying data processing, and ensuring secure access across devices, the platform addresses key challenges in managing digital twin data for industrial sites.
Asset Hosting and Data Processing
The platform supports a wide range of data formats critical for digital twins, including 3D models, LiDAR point clouds, orthomosaics, thermal imagery, and 360° panoramas. By bringing all these formats into one system, teams can manage and retrieve diverse data types from a single location.
For teams needing more than just hosting, Anvil Labs offers optional data processing services at $3 per gigapixel. This feature handles the complex task of transforming raw sensor data and imagery into formats ready for visualization and analysis. Users simply upload their raw files and receive optimized outputs, making the data easier to work with for measurements and other applications.
This centralized structure not only simplifies workflows but also makes secure data sharing more straightforward.
Secure Sharing and Cross-Device Access
Efficient data retrieval depends on accessibility, and Anvil Labs ensures users can access digital twin data from virtually any device. The platform’s cross-device compatibility allows teams to retrieve and interact with data wherever they are.
To maintain security, the platform includes robust access control features. Administrators can set permissions to determine who can view, edit, or share specific project data. This ensures sensitive information stays protected while still being available to authorized users. The Project Hosting plan, priced at $49 per project, includes secure storage and collaboration tools tailored for managing individual sites.
Integrations for Better Data Access
Anvil Labs enhances data retrieval by connecting its platform to external tools and systems. For example, its integration with Matterport allows teams to seamlessly import existing 3D scans. Additionally, AI-powered analysis tools enable automated data extraction and pattern recognition, making it easier to glean insights from hosted assets.
The platform also ties into task management systems, streamlining workflows. For instance, when thermal imagery detects temperature anomalies, the system can automatically generate maintenance tasks. These integrations bridge the gap between data retrieval and actionable decision-making, saving time and effort.
With these features, Anvil Labs ensures industrial teams can retrieve digital twin data quickly, securely, and efficiently, helping them make informed decisions faster.
Conclusion
Efficient data retrieval for large-scale digital twins depends on well-structured storage, thorough preparation, and effective retrieval methods. Streamlined storage systems play a key role in reducing data size and speeding up queries. Meanwhile, proper data preparation - like cleaning sensor data, using techniques such as PCA for dimensionality reduction, and ensuring both temporal and spatial alignment - ensures that digital twins closely represent physical assets. This alignment supports real-time updates and smooth two-way data exchange between the physical and digital worlds.
Advanced retrieval methods are equally crucial, allowing teams to access precise data exactly when needed. Real-time synchronization ensures that digital twins remain up-to-date, and techniques like Euclidean distance matching help pinpoint relevant data points efficiently. These capabilities are becoming essential as industries increasingly rely on real-time data processing.
Platforms like Anvil Labs take this a step further by simplifying data retrieval processes. By centralizing data hosting for various formats, Anvil Labs reduces the complexity of managing multiple systems. With optional data processing priced at $3 per gigapixel, secure cross-device access, and integrations with AI tools and task management software, teams can shift their focus from infrastructure management to actionable insights.
As digital twin adoption grows - currently with 30% of projects aimed at system prediction and 28% focused on simulation - having an effective data retrieval strategy is no longer optional; it’s a competitive edge. By adopting these optimized methods, organizations can enhance digital twin performance while cutting operational costs by 20-30% compared to older approaches.
FAQs
How do I choose between HDFS, NoSQL, and a lakehouse for my digital twin?
Choosing the right storage solution - whether HDFS, NoSQL, or a lakehouse - boils down to your specific data requirements and objectives.
- HDFS is a solid choice for handling large-scale batch processing and storing unstructured data, such as LiDAR files. Its strength lies in managing massive datasets efficiently.
- NoSQL shines when you need fast, flexible access to dynamic data, like sensor outputs that are constantly changing.
- A lakehouse combines real-time streaming, historical data storage, and advanced analytics. This makes it an excellent fit for digital twins, where continuous updates and sophisticated modeling are essential.
When making your decision, think about factors like scalability, the need for real-time processing, and your existing infrastructure.
What’s the minimum data prep needed before retrieval is reliable?
To keep data retrieval reliable, it's essential to set clear standards for data collection that prioritize quality and consistency. Start by standardizing metadata to ensure information is well-organized and easy to access. Protect your systems by implementing encryption and using role-based access controls to limit who can view or modify data.
Another critical step is automating data tiering, which helps optimize storage by moving data to the most appropriate storage level based on its usage. To maintain data integrity, use validation processes, error detection mechanisms, and conduct regular audits. These practices help ensure that digital twin data remains accurate, secure, and ready for effective analysis.
When should digital twin queries run at the edge vs in the cloud?
Edge computing allows you to run digital twin queries right where the action happens, enabling real-time decision-making with minimal latency. This setup is perfect for tasks like faster inspections, predictive maintenance, and quickly addressing anomalies. On the other hand, cloud-based queries shine when it comes to long-term analysis, handling large-scale storage, and performing complex computations that don’t demand immediate results.
Often, the smartest approach combines the two: use edge computing for critical, time-sensitive tasks and rely on the cloud for deeper analytics and data archiving. This hybrid strategy ensures efficiency without sacrificing depth or scalability.
